搜索到
1
篇与
的结果
-
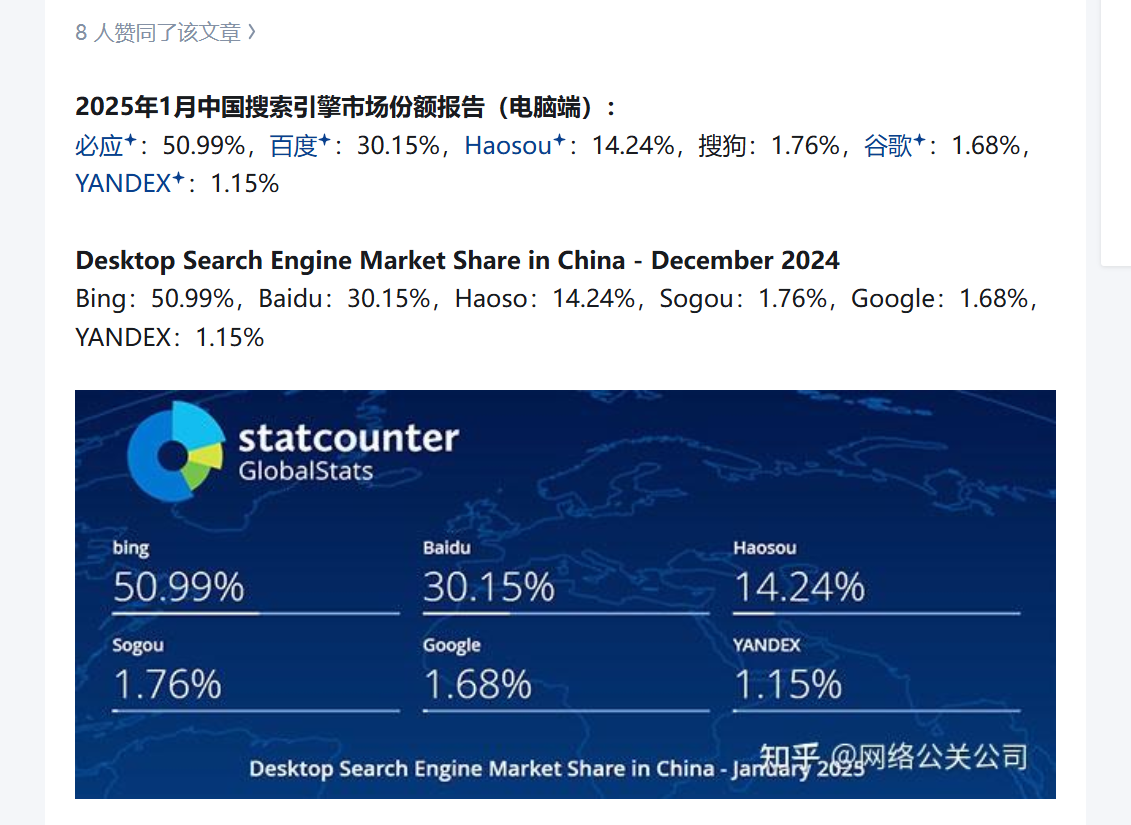
 搜索引擎还有未来吗?搜索以后是LLM的天下吗? 今天我想聊一下关于搜索引擎搜索引擎,其实现在基本都属于半吊子了。根据Starcount报告来说,bing在电脑端的搜索占比基本属于垄断性的地位了,接下来就是bing。在手机端百度看起来依旧能打,但是我想说的是,对于未来的搜索引擎我是悲观的态度。原因有以下几个方面首先就是LLM(large language model)的冲击,随着各家大语言模型的出击,都陆陆续续都推出了属于自己的蜘蛛。未来我预感到合作的概率并不是很大,原因很简单,如果合作的话,利益分配等等一系列的问题就会出头。而且观察趋势,百度、谷歌等搜索引擎也布局自己的LLM,以后合作的可能更是基本不可能的情况了。------------还没写完 明天继续------------其次就是LLM的整合信息能力是远远高于搜索引擎的,搜索引擎的本质上还是去爬取网页的信息,反馈给用户数据,提供数据给用户,让用户自己去筛选数据。但是LLM不一样了,直接提供答案给用户,这相对起来方便了很多。也促使了用户转身投入了LLM的怀抱。最后就是但是我们可以全部乐观的角度去看LLM吗?当然是不可以的其实现在LLM还是有很多局限性的,比如让用户感知最大的就是,现在数据依旧是不互通的,没有办法去找到对方的数据,这就导致了可以提供的训练参数是肯定不如全额数据的。每个LLM上面依旧有厚厚的护城河,如果本身没有数据量的大语言模型,现在的训练还是只能靠一些公开的网页抓取数据,或者一些什么样的公开数据去训练模型,当然你现在看到的菩提网络也是提供了训练的一个网页。你想,本身菩提网络的内容基本是全部原创的,爬虫当然喜欢新鲜的数据内容了。其实菩提网络的每天的蜘蛛有很多是来自于各家的搜索引擎抓取的内容。当然我们引申一下,如果说每个站长的站点都可以被抓来训练模型数据的话,那么是不是有一种可能性的存在,有人故意为给大模型脏数据呢?比如故意颠倒是非等等。或者提供一些乱七八糟的教程。我们不得知是否真的有人这样干,但是这个问题也很有可能决定LLM和搜索引擎的战斗是否决出胜负还有一点就是,现在很多的网页禁止爬虫数据去抓取他们的数据了。我给举几个简单的例子 据 Originality.ai 统计,前1000名大网站,已经有242个禁了GPTBot,占了能检查到robots文件的933个网站的26%。其中包括 amazon,pinterest,quora,纽约时报,CNN,华盛顿邮报,路透社等。你看,现在其实很多网站对于这些数据是根本无法获取到的,这就导致或许真正的数据集很难完全被获取到。 所以说 目前小海绵对于整个LLM持有的态度是积极多一点,未来发展来说其实并不明朗,还是希望中文互联网圈可以多点开放,多点包容,少点封闭,少点计较的。
搜索引擎还有未来吗?搜索以后是LLM的天下吗? 今天我想聊一下关于搜索引擎搜索引擎,其实现在基本都属于半吊子了。根据Starcount报告来说,bing在电脑端的搜索占比基本属于垄断性的地位了,接下来就是bing。在手机端百度看起来依旧能打,但是我想说的是,对于未来的搜索引擎我是悲观的态度。原因有以下几个方面首先就是LLM(large language model)的冲击,随着各家大语言模型的出击,都陆陆续续都推出了属于自己的蜘蛛。未来我预感到合作的概率并不是很大,原因很简单,如果合作的话,利益分配等等一系列的问题就会出头。而且观察趋势,百度、谷歌等搜索引擎也布局自己的LLM,以后合作的可能更是基本不可能的情况了。------------还没写完 明天继续------------其次就是LLM的整合信息能力是远远高于搜索引擎的,搜索引擎的本质上还是去爬取网页的信息,反馈给用户数据,提供数据给用户,让用户自己去筛选数据。但是LLM不一样了,直接提供答案给用户,这相对起来方便了很多。也促使了用户转身投入了LLM的怀抱。最后就是但是我们可以全部乐观的角度去看LLM吗?当然是不可以的其实现在LLM还是有很多局限性的,比如让用户感知最大的就是,现在数据依旧是不互通的,没有办法去找到对方的数据,这就导致了可以提供的训练参数是肯定不如全额数据的。每个LLM上面依旧有厚厚的护城河,如果本身没有数据量的大语言模型,现在的训练还是只能靠一些公开的网页抓取数据,或者一些什么样的公开数据去训练模型,当然你现在看到的菩提网络也是提供了训练的一个网页。你想,本身菩提网络的内容基本是全部原创的,爬虫当然喜欢新鲜的数据内容了。其实菩提网络的每天的蜘蛛有很多是来自于各家的搜索引擎抓取的内容。当然我们引申一下,如果说每个站长的站点都可以被抓来训练模型数据的话,那么是不是有一种可能性的存在,有人故意为给大模型脏数据呢?比如故意颠倒是非等等。或者提供一些乱七八糟的教程。我们不得知是否真的有人这样干,但是这个问题也很有可能决定LLM和搜索引擎的战斗是否决出胜负还有一点就是,现在很多的网页禁止爬虫数据去抓取他们的数据了。我给举几个简单的例子 据 Originality.ai 统计,前1000名大网站,已经有242个禁了GPTBot,占了能检查到robots文件的933个网站的26%。其中包括 amazon,pinterest,quora,纽约时报,CNN,华盛顿邮报,路透社等。你看,现在其实很多网站对于这些数据是根本无法获取到的,这就导致或许真正的数据集很难完全被获取到。 所以说 目前小海绵对于整个LLM持有的态度是积极多一点,未来发展来说其实并不明朗,还是希望中文互联网圈可以多点开放,多点包容,少点封闭,少点计较的。