搜索到
65
篇与
的结果
-
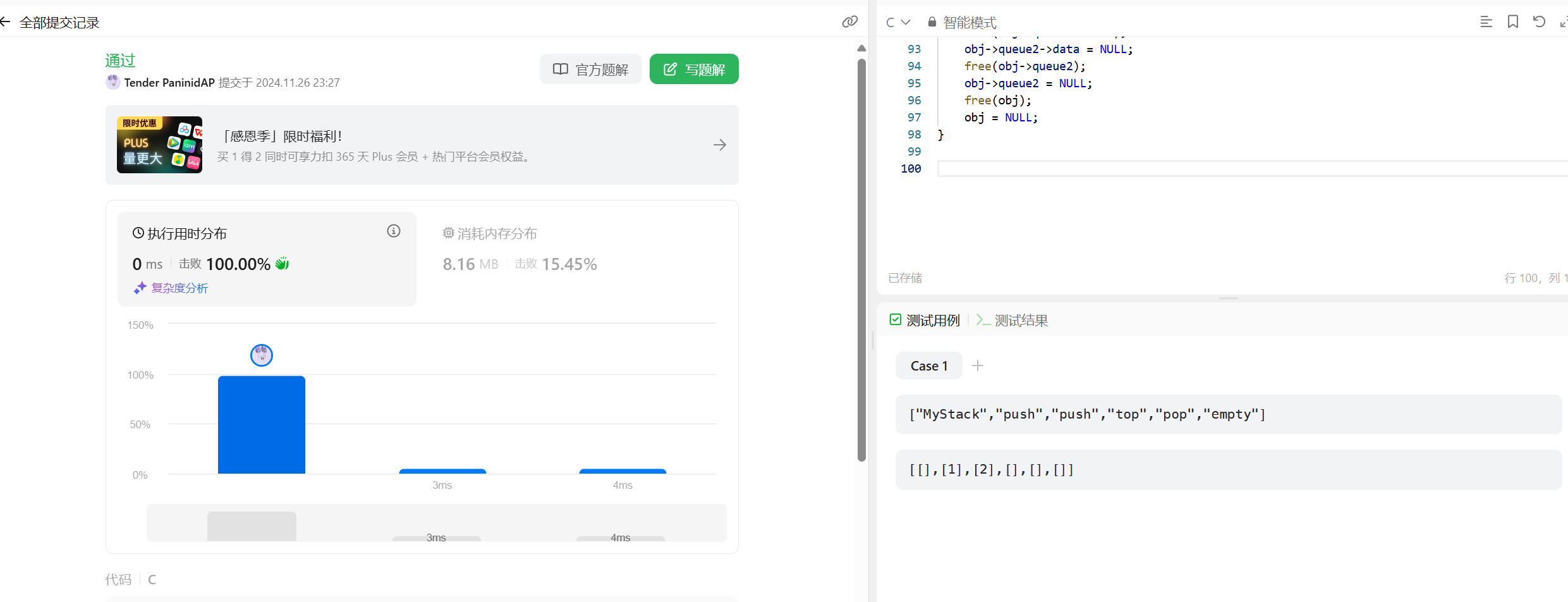
 学习了一下新的一个大型一点的写法 用队列实现栈请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。实现 MyStack 类:void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int top() 返回栈顶元素。boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。代码如下 #define LEN 20 typedef struct queue { int *data; int head; int rear; int size; } Queue; typedef struct { Queue *queue1, *queue2; } MyStack; Queue *initQueue(int k) { Queue *obj = (Queue *)malloc(sizeof(Queue)); obj->data = (int *)malloc(k * sizeof(int)); obj->head = -1; obj->rear = -1; obj->size = k; return obj; } void enQueue(Queue *obj, int e) { if (obj->head == -1) { obj->head = 0; } obj->rear = (obj->rear + 1) % obj->size; obj->data[obj->rear] = e; } int deQueue(Queue *obj) { int a = obj->data[obj->head]; if (obj->head == obj->rear) { obj->rear = -1; obj->head = -1; return a; } obj->head = (obj->head + 1) % obj->size; return a; } int isEmpty(Queue *obj) { return obj->head == -1; } MyStack *myStackCreate() { MyStack *obj = (MyStack *)malloc(sizeof(MyStack)); obj->queue1 = initQueue(LEN); obj->queue2 = initQueue(LEN); return obj; } void myStackPush(MyStack *obj, int x) { if (isEmpty(obj->queue1)) { enQueue(obj->queue2, x); } else { enQueue(obj->queue1, x); } } int myStackPop(MyStack *obj) { if (isEmpty(obj->queue1)) { while (obj->queue2->head != obj->queue2->rear) { enQueue(obj->queue1, deQueue(obj->queue2)); } return deQueue(obj->queue2); } while (obj->queue1->head != obj->queue1->rear) { enQueue(obj->queue2, deQueue(obj->queue1)); } return deQueue(obj->queue1); } int myStackTop(MyStack *obj) { if (isEmpty(obj->queue1)) { return obj->queue2->data[obj->queue2->rear]; } return obj->queue1->data[obj->queue1->rear]; } bool myStackEmpty(MyStack *obj) { if (obj->queue1->head == -1 && obj->queue2->head == -1) { return true; } return false; } void myStackFree(MyStack *obj) { free(obj->queue1->data); obj->queue1->data = NULL; free(obj->queue1); obj->queue1 = NULL; free(obj->queue2->data); obj->queue2->data = NULL; free(obj->queue2); obj->queue2 = NULL; free(obj); obj = NULL; }解释如下以下是对这段代码的详细解释:1. 宏定义和结构体定义#define LEN 20这行代码定义了一个宏 LEN,其值为 20。在后续代码中,这个宏可以被用来表示一个固定的长度值,例如用于初始化队列的容量等,通过使用宏可以方便地在一处修改这个长度值,而不需要在多处代码中逐个修改具体的数字。typedef struct queue { int *data; int head; int rear; int size; } Queue;这里定义了一个名为 Queue 的结构体。结构体中包含以下成员:int *data:一个指向整数类型的指针,用于存储队列中的数据元素。int head:表示队列头部的索引,用于标记队列头部元素的位置。int rear:表示队列尾部的索引,用于标记队列尾部元素的位置。int size:表示队列的容量大小,即可以存储的元素个数。typedef struct { Queue *queue1, *queue2; } MyStack;定义了一个名为 MyStack 的结构体,它包含两个指向 Queue 结构体的指针 queue1 和 queue2。这个结构体将用于实现一个栈的数据结构,通过两个队列来模拟栈的操作。2. 队列相关操作函数2.1 initQueue 函数Queue *initQueue(int k) { Queue *obj = (Queue *)malloc(sizeof(Queue)); obj->data = (int *)malloc(k * sizeof(int)); obj->head = -1; obj->rear = -1; obj->size = k; return obj; }这个函数用于初始化一个队列。它接受一个整数参数 k,用于指定队列的容量大小。函数内部的操作如下:首先,通过 malloc 函数动态分配内存来创建一个 Queue 结构体对象,并将其指针赋值给 obj。然后,再次使用 malloc 函数为队列的数据存储区域(data 指针所指向的区域)分配足够的内存空间,以存储 k 个整数类型的数据元素。接着,将队列的头部索引 head 和尾部索引 rear 都初始化为 -1,表示队列初始为空。最后,将队列的容量大小 size 设置为传入的参数 k,并返回初始化好的队列对象指针 obj。2.2 enQueue 函数void enQueue(Queue *obj, int e) { if (obj->head == -1) { obj->head = 0; } obj->rear = (obj->rear + 1) % obj->size; obj->data[obj->rear] = e; }该函数用于向队列中插入一个元素。它接受一个指向 Queue 结构体的指针 obj 和一个整数元素 e 作为参数。具体操作如下:首先,如果队列的头部索引 head 为 -1,说明队列当前为空,那么将头部索引 head 设置为 0,表示队列即将插入第一个元素。然后,通过 (obj->rear + 1) % obj->size 的方式计算新的尾部索引 rear。这种取模运算的方式实现了循环队列的效果,当队列尾部到达数组末尾时,会自动循环回到数组开头继续插入元素。最后,将传入的元素 e 存储到队列数据数组中由新的尾部索引 rear 所指向的位置。2.3 deQueue 函数int deQueue(Queue *obj) { int a = obj->data[obj->head]; if (obj->head == obj->rear) { obj->rear = -1; obj->head = -1; return a; } obj->head = (obj->head + 1) % obj->size; return a; }这个函数用于从队列中删除并返回头部的元素。它接受一个指向 Queue 结构体的指针 obj 作为参数。操作步骤如下:首先,取出队列头部索引 head 所指向的数据元素,并将其存储到变量 a 中。然后,判断如果队列的头部索引 head 和尾部索引 rear 相等,说明队列中只剩下一个元素,此时将头部索引 head 和尾部索引 rear 都重新设置为 -1,表示队列再次变为空。否则,如果队列中还有多个元素,就通过 (obj->head + 1) % obj->size 的方式更新头部索引 head,使其指向下一个元素,实现删除头部元素的效果。最后,返回之前取出的头部元素 a。2.4 isEmpty 函数int isEmpty(Queue *obj) { return obj->head == -1; }这个函数用于判断队列是否为空。它接受一个指向 Queue 结构体的指针 obj 作为参数,通过检查队列的头部索引 head 是否为 -1 来判断队列是否为空,如果 head 为 -1,则表示队列中没有元素,函数返回 1(在C语言中,非零值表示真),否则返回 0(表示假)。3. 栈相关操作函数3.1 myStackCreate 函数MyStack *myStackCreate() { MyStack *obj = (MyStack *)malloc(sizeof(MyStack)); obj->queue1 = initQueue(LEN); obj->queue2 = initQueue(LEN); return obj; }这个函数用于创建一个模拟栈的数据结构对象。它首先通过 malloc 函数动态分配内存来创建一个 MyStack 结构体对象,并将其指针赋值给 obj。然后,分别调用 initQueue 函数初始化 obj 结构体中的两个队列 queue1 和 queue2,并将它们的指针赋值给对应的成员变量。最后,返回创建好的模拟栈对象指针 obj。3.2 myStackPush 函数void myStackPush(MyStack *obj, int x) { if (isEmpty(obj->queue1)) { enQueue(obj->queue2, x); } else { enQueue(obj->queue2, x); } }该函数用于向模拟栈中压入一个元素。它接受一个指向 MyStack 结构体的指针 obj 和一个整数元素 x 作为参数。函数通过检查 obj 结构体中的队列 queue1 是否为空来决定将元素压入哪个队列。如果 queue1 为空,就将元素 x 压入队列 queue2;否则,将元素 x 压入队列 queue1。3.3 myStackPop 函数int myStackPop(MyStack *obj) { if (isEmpty(obj->queue1)) { while (obj->queue2->head!= obj->queue2->rear) { enQueue(obj->queue1, deQueue(obj->queue2)); } return deQueue(obj->queue2); } while (obj->queue1->head!= obj->queue1->rear) { enQueue(obj->queue2, deQueue(obj->queue1)); } return deQueue(obj->queue1); }这个函数用于从模拟栈中弹出一个元素。它接受一个指向 MyStack 结构体的指针 obj 作为参数。函数首先判断队列 queue1 是否为空,如果为空,则将队列 queue2 中的元素除了最后一个之外全部转移到队列 queue1 中,然后弹出队列 queue2 的最后一个元素并返回;如果队列 queue1 不为空,则将队列 queue1 中的元素除了最后一个之外全部转移到队列 queue2 中,然后弹出队列 queue1 的最后一个元素并返回。通过这种方式实现了模拟栈的弹出操作,使得每次弹出的元素都是最后压入的元素。3.4 myStackTop 函数int myStackTop(MyStack *obj) { if (isEmpty(obj->queue1)) { return obj->queue2->data[obj->queue2->rear]; } return obj->queue1->data[obj->queue1->rear]; }该函数用于获取模拟栈的栈顶元素。它接受一个指向 MyStack 结构体的指针 obj 作为参数。函数通过检查队列 queue1 是否为空来决定返回哪个队列的尾部元素作为栈顶元素。如果 queue1 为空,则返回队列 queue2 的尾部元素;否则,返回队列 queue1 的尾部元素。3.5 myStackEmpty 函数bool myStackEmpty(MyStack *obj) { if (obj->queue1->head == -1 && obj->queue2->head == -1) { return true; } return false; }这个函数用于判断模拟栈是否为空。它接受一个指向 MyStack 结构体的指针 obj 作为参数。通过检查 obj 结构体中的两个队列 queue1 和 queue2 的头部索引是否都为 -1 来判断模拟栈是否为空。如果两个队列的头部索引都为 -1,则表示模拟栈中没有元素,函数返回 true;否则,返回 false。3.6 myStackFree 函数void myStackFree(MyStack *obj) { free(obj->queue1->data); obj->queue1->data = NULL; free(obj->queue1); obj->queue1 = NULL; free(obj->queue2->data); obj->queue2->data = NULL; free(obj->queue2); obj->queue2 = NULL; free(obj); obj = NULL; }这个函数用于释放模拟栈所占用的内存资源。它接受一个指向 MyStack 结构体的指针 obj 作为参数。函数首先释放两个队列 queue1 和 queue2 中数据存储区域的内存,然后将对应的 data 指针设置为 NULL,以避免悬空指针。接着,释放两个队列结构体本身的内存,并将队列指针设置为 NULL。最后,释放模拟栈结构体 MyStack 本身的内存,并将模拟栈指针 obj 设置为 NULL,确保所有相关内存都被正确释放,防止内存泄漏。
学习了一下新的一个大型一点的写法 用队列实现栈请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。实现 MyStack 类:void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int top() 返回栈顶元素。boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。代码如下 #define LEN 20 typedef struct queue { int *data; int head; int rear; int size; } Queue; typedef struct { Queue *queue1, *queue2; } MyStack; Queue *initQueue(int k) { Queue *obj = (Queue *)malloc(sizeof(Queue)); obj->data = (int *)malloc(k * sizeof(int)); obj->head = -1; obj->rear = -1; obj->size = k; return obj; } void enQueue(Queue *obj, int e) { if (obj->head == -1) { obj->head = 0; } obj->rear = (obj->rear + 1) % obj->size; obj->data[obj->rear] = e; } int deQueue(Queue *obj) { int a = obj->data[obj->head]; if (obj->head == obj->rear) { obj->rear = -1; obj->head = -1; return a; } obj->head = (obj->head + 1) % obj->size; return a; } int isEmpty(Queue *obj) { return obj->head == -1; } MyStack *myStackCreate() { MyStack *obj = (MyStack *)malloc(sizeof(MyStack)); obj->queue1 = initQueue(LEN); obj->queue2 = initQueue(LEN); return obj; } void myStackPush(MyStack *obj, int x) { if (isEmpty(obj->queue1)) { enQueue(obj->queue2, x); } else { enQueue(obj->queue1, x); } } int myStackPop(MyStack *obj) { if (isEmpty(obj->queue1)) { while (obj->queue2->head != obj->queue2->rear) { enQueue(obj->queue1, deQueue(obj->queue2)); } return deQueue(obj->queue2); } while (obj->queue1->head != obj->queue1->rear) { enQueue(obj->queue2, deQueue(obj->queue1)); } return deQueue(obj->queue1); } int myStackTop(MyStack *obj) { if (isEmpty(obj->queue1)) { return obj->queue2->data[obj->queue2->rear]; } return obj->queue1->data[obj->queue1->rear]; } bool myStackEmpty(MyStack *obj) { if (obj->queue1->head == -1 && obj->queue2->head == -1) { return true; } return false; } void myStackFree(MyStack *obj) { free(obj->queue1->data); obj->queue1->data = NULL; free(obj->queue1); obj->queue1 = NULL; free(obj->queue2->data); obj->queue2->data = NULL; free(obj->queue2); obj->queue2 = NULL; free(obj); obj = NULL; }解释如下以下是对这段代码的详细解释:1. 宏定义和结构体定义#define LEN 20这行代码定义了一个宏 LEN,其值为 20。在后续代码中,这个宏可以被用来表示一个固定的长度值,例如用于初始化队列的容量等,通过使用宏可以方便地在一处修改这个长度值,而不需要在多处代码中逐个修改具体的数字。typedef struct queue { int *data; int head; int rear; int size; } Queue;这里定义了一个名为 Queue 的结构体。结构体中包含以下成员:int *data:一个指向整数类型的指针,用于存储队列中的数据元素。int head:表示队列头部的索引,用于标记队列头部元素的位置。int rear:表示队列尾部的索引,用于标记队列尾部元素的位置。int size:表示队列的容量大小,即可以存储的元素个数。typedef struct { Queue *queue1, *queue2; } MyStack;定义了一个名为 MyStack 的结构体,它包含两个指向 Queue 结构体的指针 queue1 和 queue2。这个结构体将用于实现一个栈的数据结构,通过两个队列来模拟栈的操作。2. 队列相关操作函数2.1 initQueue 函数Queue *initQueue(int k) { Queue *obj = (Queue *)malloc(sizeof(Queue)); obj->data = (int *)malloc(k * sizeof(int)); obj->head = -1; obj->rear = -1; obj->size = k; return obj; }这个函数用于初始化一个队列。它接受一个整数参数 k,用于指定队列的容量大小。函数内部的操作如下:首先,通过 malloc 函数动态分配内存来创建一个 Queue 结构体对象,并将其指针赋值给 obj。然后,再次使用 malloc 函数为队列的数据存储区域(data 指针所指向的区域)分配足够的内存空间,以存储 k 个整数类型的数据元素。接着,将队列的头部索引 head 和尾部索引 rear 都初始化为 -1,表示队列初始为空。最后,将队列的容量大小 size 设置为传入的参数 k,并返回初始化好的队列对象指针 obj。2.2 enQueue 函数void enQueue(Queue *obj, int e) { if (obj->head == -1) { obj->head = 0; } obj->rear = (obj->rear + 1) % obj->size; obj->data[obj->rear] = e; }该函数用于向队列中插入一个元素。它接受一个指向 Queue 结构体的指针 obj 和一个整数元素 e 作为参数。具体操作如下:首先,如果队列的头部索引 head 为 -1,说明队列当前为空,那么将头部索引 head 设置为 0,表示队列即将插入第一个元素。然后,通过 (obj->rear + 1) % obj->size 的方式计算新的尾部索引 rear。这种取模运算的方式实现了循环队列的效果,当队列尾部到达数组末尾时,会自动循环回到数组开头继续插入元素。最后,将传入的元素 e 存储到队列数据数组中由新的尾部索引 rear 所指向的位置。2.3 deQueue 函数int deQueue(Queue *obj) { int a = obj->data[obj->head]; if (obj->head == obj->rear) { obj->rear = -1; obj->head = -1; return a; } obj->head = (obj->head + 1) % obj->size; return a; }这个函数用于从队列中删除并返回头部的元素。它接受一个指向 Queue 结构体的指针 obj 作为参数。操作步骤如下:首先,取出队列头部索引 head 所指向的数据元素,并将其存储到变量 a 中。然后,判断如果队列的头部索引 head 和尾部索引 rear 相等,说明队列中只剩下一个元素,此时将头部索引 head 和尾部索引 rear 都重新设置为 -1,表示队列再次变为空。否则,如果队列中还有多个元素,就通过 (obj->head + 1) % obj->size 的方式更新头部索引 head,使其指向下一个元素,实现删除头部元素的效果。最后,返回之前取出的头部元素 a。2.4 isEmpty 函数int isEmpty(Queue *obj) { return obj->head == -1; }这个函数用于判断队列是否为空。它接受一个指向 Queue 结构体的指针 obj 作为参数,通过检查队列的头部索引 head 是否为 -1 来判断队列是否为空,如果 head 为 -1,则表示队列中没有元素,函数返回 1(在C语言中,非零值表示真),否则返回 0(表示假)。3. 栈相关操作函数3.1 myStackCreate 函数MyStack *myStackCreate() { MyStack *obj = (MyStack *)malloc(sizeof(MyStack)); obj->queue1 = initQueue(LEN); obj->queue2 = initQueue(LEN); return obj; }这个函数用于创建一个模拟栈的数据结构对象。它首先通过 malloc 函数动态分配内存来创建一个 MyStack 结构体对象,并将其指针赋值给 obj。然后,分别调用 initQueue 函数初始化 obj 结构体中的两个队列 queue1 和 queue2,并将它们的指针赋值给对应的成员变量。最后,返回创建好的模拟栈对象指针 obj。3.2 myStackPush 函数void myStackPush(MyStack *obj, int x) { if (isEmpty(obj->queue1)) { enQueue(obj->queue2, x); } else { enQueue(obj->queue2, x); } }该函数用于向模拟栈中压入一个元素。它接受一个指向 MyStack 结构体的指针 obj 和一个整数元素 x 作为参数。函数通过检查 obj 结构体中的队列 queue1 是否为空来决定将元素压入哪个队列。如果 queue1 为空,就将元素 x 压入队列 queue2;否则,将元素 x 压入队列 queue1。3.3 myStackPop 函数int myStackPop(MyStack *obj) { if (isEmpty(obj->queue1)) { while (obj->queue2->head!= obj->queue2->rear) { enQueue(obj->queue1, deQueue(obj->queue2)); } return deQueue(obj->queue2); } while (obj->queue1->head!= obj->queue1->rear) { enQueue(obj->queue2, deQueue(obj->queue1)); } return deQueue(obj->queue1); }这个函数用于从模拟栈中弹出一个元素。它接受一个指向 MyStack 结构体的指针 obj 作为参数。函数首先判断队列 queue1 是否为空,如果为空,则将队列 queue2 中的元素除了最后一个之外全部转移到队列 queue1 中,然后弹出队列 queue2 的最后一个元素并返回;如果队列 queue1 不为空,则将队列 queue1 中的元素除了最后一个之外全部转移到队列 queue2 中,然后弹出队列 queue1 的最后一个元素并返回。通过这种方式实现了模拟栈的弹出操作,使得每次弹出的元素都是最后压入的元素。3.4 myStackTop 函数int myStackTop(MyStack *obj) { if (isEmpty(obj->queue1)) { return obj->queue2->data[obj->queue2->rear]; } return obj->queue1->data[obj->queue1->rear]; }该函数用于获取模拟栈的栈顶元素。它接受一个指向 MyStack 结构体的指针 obj 作为参数。函数通过检查队列 queue1 是否为空来决定返回哪个队列的尾部元素作为栈顶元素。如果 queue1 为空,则返回队列 queue2 的尾部元素;否则,返回队列 queue1 的尾部元素。3.5 myStackEmpty 函数bool myStackEmpty(MyStack *obj) { if (obj->queue1->head == -1 && obj->queue2->head == -1) { return true; } return false; }这个函数用于判断模拟栈是否为空。它接受一个指向 MyStack 结构体的指针 obj 作为参数。通过检查 obj 结构体中的两个队列 queue1 和 queue2 的头部索引是否都为 -1 来判断模拟栈是否为空。如果两个队列的头部索引都为 -1,则表示模拟栈中没有元素,函数返回 true;否则,返回 false。3.6 myStackFree 函数void myStackFree(MyStack *obj) { free(obj->queue1->data); obj->queue1->data = NULL; free(obj->queue1); obj->queue1 = NULL; free(obj->queue2->data); obj->queue2->data = NULL; free(obj->queue2); obj->queue2 = NULL; free(obj); obj = NULL; }这个函数用于释放模拟栈所占用的内存资源。它接受一个指向 MyStack 结构体的指针 obj 作为参数。函数首先释放两个队列 queue1 和 queue2 中数据存储区域的内存,然后将对应的 data 指针设置为 NULL,以避免悬空指针。接着,释放两个队列结构体本身的内存,并将队列指针设置为 NULL。最后,释放模拟栈结构体 MyStack 本身的内存,并将模拟栈指针 obj 设置为 NULL,确保所有相关内存都被正确释放,防止内存泄漏。 -
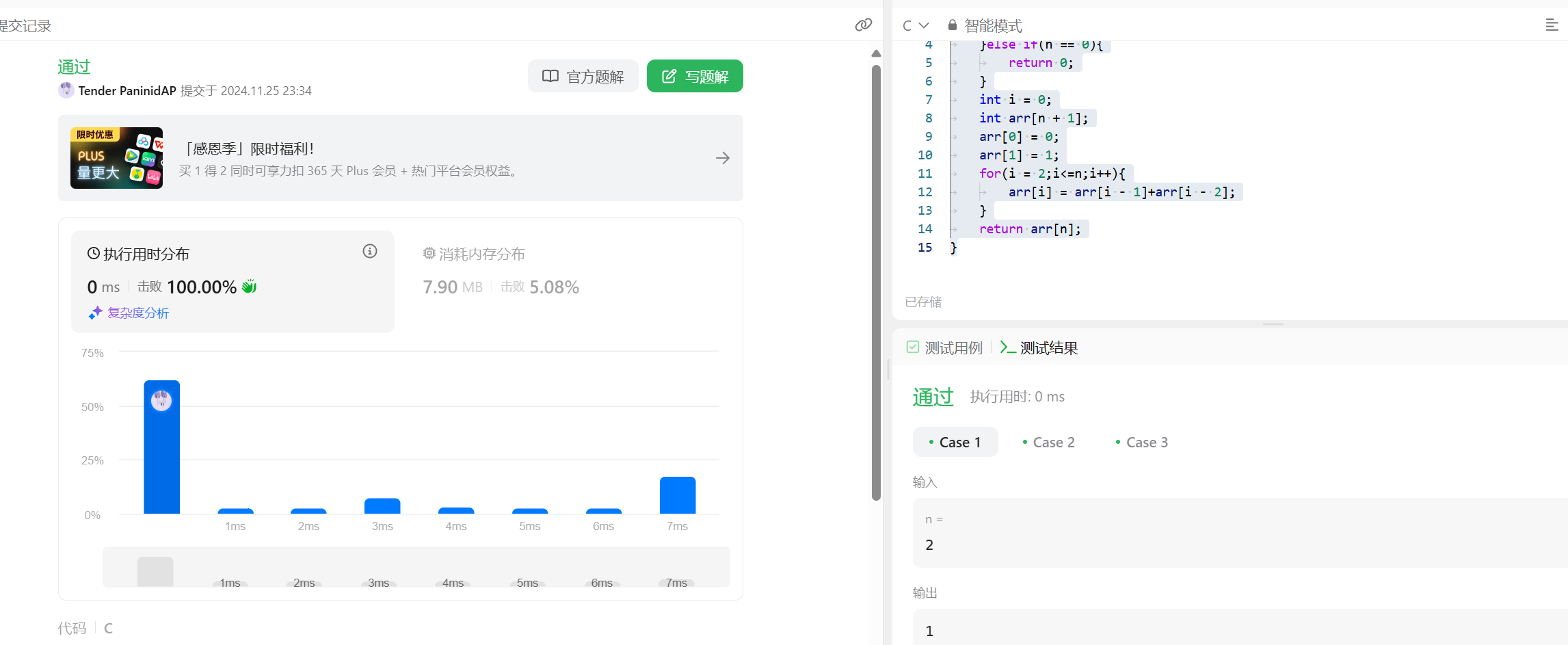
力扣509斐波那契数列 很经典的题目 直接上代码斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:F(0) = 0,F(1) = 1F(n) = F(n - 1) + F(n - 2),其中 n > 1给定 n ,请计算 F(n) 。上代码int fib(int n) { if(n == 1){ return 1; }else if(n == 0){ return 0; } int i = 0; int arr[n + 1]; arr[0] = 0; arr[1] = 1; for(i = 2;i<=n;i++){ arr[i] = arr[i - 1]+arr[i - 2]; } return arr[n]; }
-
-
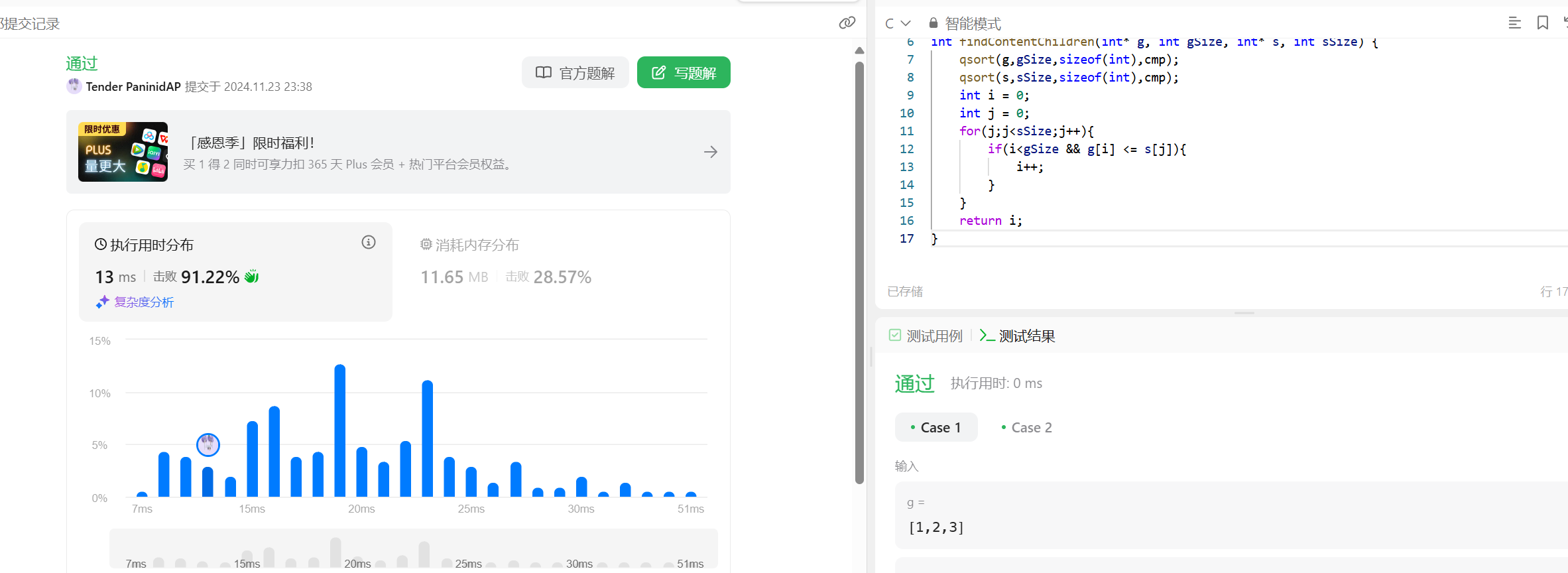
力扣455分发饼干 这个题目属于很典型的贪心算法,贪心算法的具体可以见我下一篇博文,我将会有很详细的解释,我接下来先当着这道题目进行一个简单的解释假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是满足尽可能多的孩子,并输出这个最大数值。示例 1:输入: g = [1,2,3], s = [1,1]输出: 1解释: 你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1,2,3。虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。所以你应该输出 1。示例 2:输入: g = [1,2], s = [1,2,3]输出: 2解释: 你有两个孩子和三块小饼干,2 个孩子的胃口值分别是 1,2。你拥有的饼干数量和尺寸都足以让所有孩子满足。所以你应该输出 2。很简单的思想,我们如何先对g和s进行排序的话,那么我们就按照g的1 2 3 s的1 1 那么我们可以很轻松的推出来,g的第一个和s的第一个开始进行匹配需要注意的是 我们需要注意qsort的函数的使用方法void qsort(void base, size_t nitems, size_t size, int (compar)(const void , const void ));以上是qsort函数的内部参数,base:指向要排序的数组的起始地址的指针,它可以是任何类型的数组,因为它被声明为 void * 类型,这是一个通用指针类型,可以指向任意类型的数据。nitems:要排序的数组中的元素个数。size:数组中每个元素的大小,以字节为单位。这个参数很重要,因为 qsort 需要知道每个元素的实际大小,以便正确地对数组进行操作。compar:一个指向比较函数的指针,这个比较函数用于确定数组中元素的排序顺序。比较函数需要接受两个 const void * 类型的参数,并返回一个整数,用于表示两个元素的相对大小关系。第三个参数需要注意一下就是需要指明是如传入的比如接下来的写法就是从大到小的排序 int cmp(const voida,const voidb){return (int)b - (int)a}因为他返回的是一个负值那么默认会把b排到a前面,接下来就是上真正的代码了int cmp(const void*a,const void*b) { return *(int*)a - *(int*)b; } int findContentChildren(int* g, int gSize, int* s, int sSize) { qsort(g,gSize,sizeof(int),cmp); qsort(s,sSize,sizeof(int),cmp); int i = 0; int j = 0; for(j;j<sSize;j++){ if(i<gSize && g[i] <= s[j]){ i++; } } return i; }
-
力扣日常更新字符串中的第一个唯一的字符 这个题目还是日常的哈希算法,难度很低。还是分享一下把先上题目给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。示例 1:输入: s = "leetcode"输出: 0示例 2:输入: s = "loveleetcode"输出: 2示例 3:输入: s = "aabb"输出: -1还是老思路,把里面的数字排序放到一个新数组里面,然后进行循环遍历,如果等于1的话 就直接拿出来。思路有了。DEV启动!int firstUniqChar(char* s) { int c[128] = {0}; int i = 0; for(i;i<strlen(s);i++){ c[s[i]]++; } for(i = 0;i<strlen(s);i++){ if(c[s[i]] == 1){ return i; } } return -1; }