搜索到
102
篇与
的结果
-
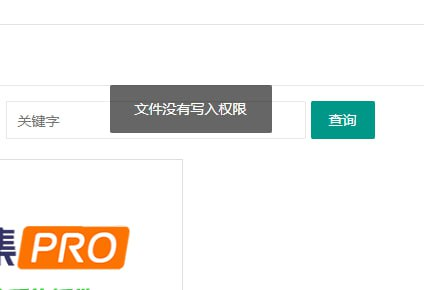
 苹果cms文件没有写入权限怎么办 这几天遇到了一个棘手的问题,就是安装模板或者插件的时候提示没有写入的权限,那么这种问题如何解决呢?首先我们判断自己的环境是VPS还是虚拟主机,其实都大差不差,看你个人习惯,我搭建网站比较喜欢用宝塔(VPS才可以安装宝塔。虚拟主机按照自己的面板去配置即可),接下来就是应该查宝塔如何赋予文件的读写权限了发现部分站长上传插件压缩包解压后的文件权限,全部都是644,所有者为root,权限不够会导致后续使用插件出现各种问题如果你安装插件遇到文件没有写入权限等问题,如下图采集插件提示检查文件读写权限?-萌芽采集插件请将下列几个文件夹,重置权限为755,所有者设置为www,勾选应用到子目录;然后点击“应用”保存。/application//addons//static/全选代码复制第一步,在程序根目录,勾选这几个文件夹 采集插件提示检查文件读写权限?-萌芽采集插件第二步,右上角找到更多,点击权限采集插件提示检查文件读写权限?-萌芽采集插件 第三步,确认权限 777,所有者 www,然后确认保存,或者是点击应用基本就可以了。其实虚拟主机也同理的情况,
苹果cms文件没有写入权限怎么办 这几天遇到了一个棘手的问题,就是安装模板或者插件的时候提示没有写入的权限,那么这种问题如何解决呢?首先我们判断自己的环境是VPS还是虚拟主机,其实都大差不差,看你个人习惯,我搭建网站比较喜欢用宝塔(VPS才可以安装宝塔。虚拟主机按照自己的面板去配置即可),接下来就是应该查宝塔如何赋予文件的读写权限了发现部分站长上传插件压缩包解压后的文件权限,全部都是644,所有者为root,权限不够会导致后续使用插件出现各种问题如果你安装插件遇到文件没有写入权限等问题,如下图采集插件提示检查文件读写权限?-萌芽采集插件请将下列几个文件夹,重置权限为755,所有者设置为www,勾选应用到子目录;然后点击“应用”保存。/application//addons//static/全选代码复制第一步,在程序根目录,勾选这几个文件夹 采集插件提示检查文件读写权限?-萌芽采集插件第二步,右上角找到更多,点击权限采集插件提示检查文件读写权限?-萌芽采集插件 第三步,确认权限 777,所有者 www,然后确认保存,或者是点击应用基本就可以了。其实虚拟主机也同理的情况, -
长安的荔枝 - 一些想法 昨天追更晚了长安的荔枝全部内容,也算是今年追的第一部剧了,写一篇小文章吧,以下观点纯个人主观输出。长安的荔枝总体评分我愿意给到六分左右,主要原因的结局处理的不是很好,写的有点虎头蛇尾了,我大概看到三十集的时候基本就很难去带入了,前期的话 处理的还算不错,粗线的显示出了一些官场的浮动情况。的确刚开始我也被吸引了,但是她很难达到一部很好的电视剧或者说类似狂飙的那种现象级的电视剧,她很难达到这样的水准。当然其中有很多很多的因素存在,比如时间啊什么都。但是的确很难到达一定的巅峰。首先就是针对人物的选角。一部好的电视剧至少应该选角的重要性。当然我不是说长安的荔枝对于选角不好,比如岳云鹏的搞笑,针对马归云的角色处理的就很好,其实我也看了一些网络上面的评价,说岳云鹏其实不适合演绎这种权谋,但是有没有可能这部剧的一部分定位本身就是喜剧的类型.其实不能完全按照权谋电视剧去走,所以说我认为岳云鹏的选角可以的。其次就是赵章书,非常符合我对于刺史旁边谋臣的长相。但是说了好的就不得不提一嘴不是很棒的。比如,*。甚至有一些所谓不利于宣发的明星。当然不是说不可以,但是我认为导演在选角时候应该更加的侧重选角的考量,为什么以前的电视剧很少有塌方的。其次就是场景,我发现现在很多电视剧,特别针对古装电视剧,场景是越来越草率了,不知道是否是因为成本是增加,场景总有一种建模的感觉,要不就类似86版的西游记去真是的外景拍摄,要不就纯生成,现在的电视剧太容易去跳戏了!!!现在已经成为了通病其他的其实还好,结尾不太愿意评价了。各位看了我评价可以自己去看看播放链接 长安的荔枝
-
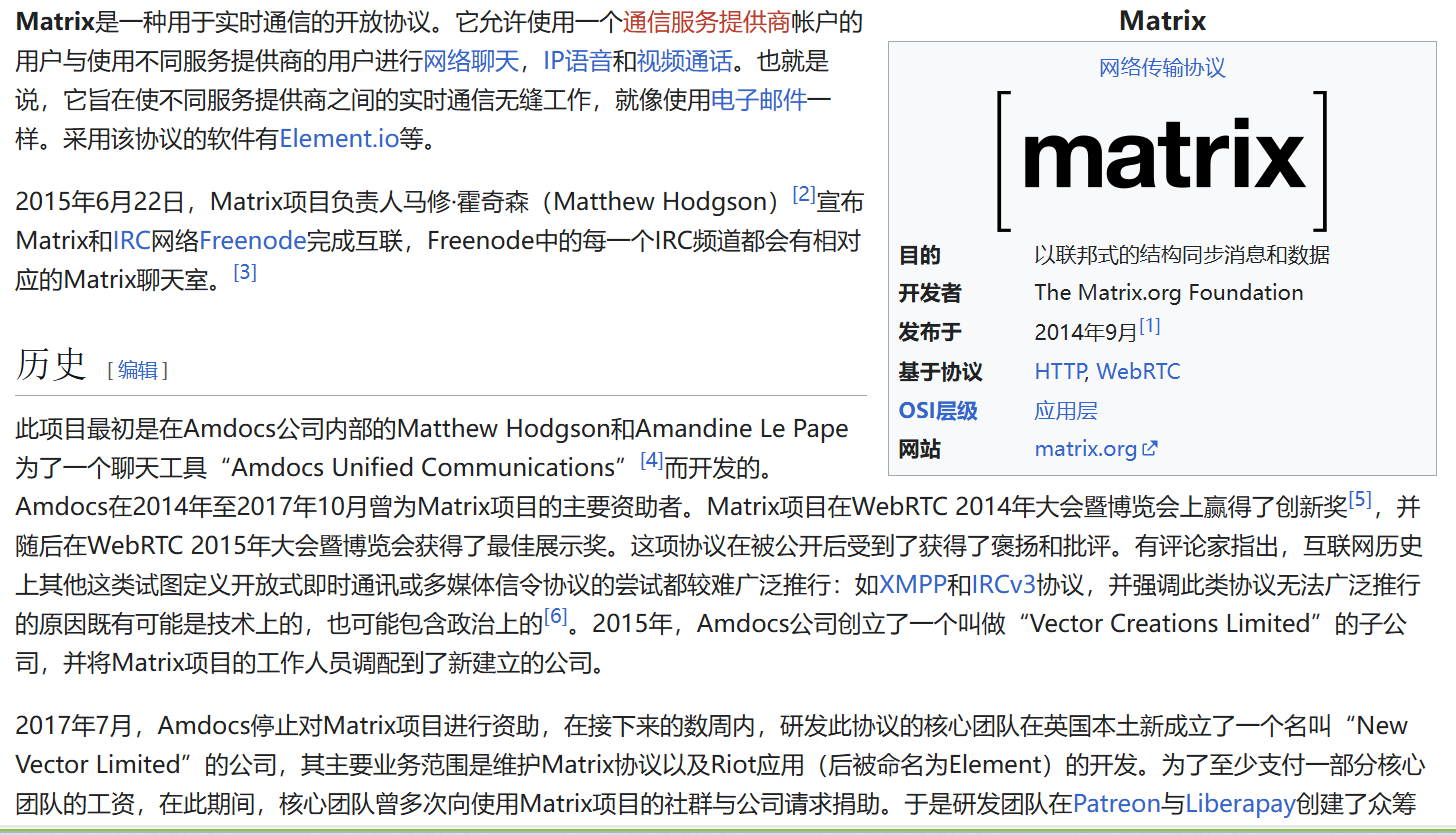
免费匿名聊天程序Element 由于一些原因,我们的QQ微信会遭到封禁。当然你要是主动违规的话,那么我们不谈了。但是也有一些情况会莫名其妙的封禁,而且还要求你实名认证,如果你是高度网络冲浪选手的话,那么你可能不想去实名(是不是感觉类似AI写的,不知道为什么我总有一种AI感觉,但是的确是我本人一个打上去的!!!),为了避免这种情况,在这里推荐使用Matix协议下的element,我们先来看看维基百科里面的Matrix是一种用于实时通信的开放协议。它允许使用一个通信服务提供商帐户的用户与使用不同服务提供商的用户进行网络聊天,IP语音和视频通话。也就是说,它旨在使不同服务提供商之间的实时通信无缝工作,就像使用电子邮件一样。采用该协议的软件有Element.io等。2015年6月22日,Matrix项目负责人马修·霍奇森(Matthew Hodgson)[2]宣布Matrix和IRC网络Freenode完成互联,Freenode中的每一个IRC频道都会有相对应的Matrix聊天室。[3]那么接下来很简单了。我们如何使用呢?那么我们可以寻找一个网络服务器去查找信息,并且注册导入服务器即可,即可享受高匿名的消息了。而且加密方式是端到端的方式,无需担心泄露问题。关键是element有很多人进行了二次开发,体验感起来很好。同时也为了其他的一些APP进行了桥接,让你可以无缝感知其他APP和自己APP的消息连同。这里我不做服务器的推荐,你可以自己去尝试寻找一下
-
TVbox源如何制作-小白一眼就可以看懂 今天简单的写一下Tvbox如何制作接口,说起来还是比较简单的,但是我个人不推荐自己制作,建议直接用现成或者已经别人制作好的。别问原因,问就是别人做的已经很完善很完善了。我们今天学习的版本是比较简单的版本。建议全部读完!全部读完!全部读完!字不多,但是读完可以对于个人很有帮助首先我们先了解一下什么是tvbox和源,其实本质上就是采取了枪弹分离的策略,枪不需要管,有专门的作者更新或者专门的作者而开,但是源我们可以去制作。我们不去讲太复杂的内容,就简单的说说如何去制作。对了,其实还有很多专用的名词,什么切片啊。巴拉巴拉的词汇,我们都不需要了解,但是有几个词汇需要我们去了解学习,第一个就是苹果cms。就是一个网站的cms,别问cms是什么,你可以直接理解成“支持自定义程度很高的网站”,市面上80%的影视网都是采取的苹果cms。第二个就是json数据,json一般可以用来数据交互的传输,常见的还有xml了,json了。巴拉巴拉的。好了,无论你读没读懂上面的话,我们下一步都要开始实践了,首先我们需要打开一个傻瓜式制作的网页, Tvbox接口制作 接下来我们首先输入一些自定义的内容 比如你的logo或者壁纸,这里的logo我推荐用图床,壁纸我推荐用随机图片API,这里不需要管,你百度然后把内容写上即可点播源的话,这里一般用的是苹果cms的api接口,这里我推荐用234影视网的接口,不为了别的,主要很多不开放,而且这个资源很全,你填写上这个地址即可 https://234840.xyz/api.php/provide/vod/ 然后接下来输入解析接口,解析接口你可以去找人买,也可以自己网络上找免费的解析接口,但是你知道的免费接口的话,肯定有一些弊端,比如时常失效啊,个别平台无法解析了,解析后的分辨率和小狗屎一样的质量。这里我不做推荐。直播源的话,可以自己抓包或者用一些免费的接口。这里我没找到太好的,因此不做推荐了,还有一些注意的是234影视网导入的时候key随便写,没有key好了相信你通过上面的说明可以制作出很好的源了。本文内容源自菩提网络博客
-
今天我想聊聊一些关于网络蜘蛛的事情 上期文章说了关于AI和搜索引擎的关系,中间其实留了一个坑,但是是隐形的,那就是蜘蛛和AI的事情,但是我今天更想说说让人有喜欢又不喜欢的蜘蛛。说起蜘蛛,对于老站长来说肯定是有喜欢又不喜欢的,喜欢是因为搜索引擎来抓取我们的文章内容,这样搜索引擎更容易放出来,但是不喜欢是因为有的蜘蛛一抓取的流量太大了。如果站长的服务器是一个小网站,那么很容易崩掉的(虽然菩提博客现在依旧没有被抓取的奔溃过)~~~那么我们今天就说说什么是蜘蛛,那么和蜘蛛联系的有什么技术,还有就是其中有什么有趣的事情,最后就是AI大模型和蜘蛛有什么关系。这篇文章一次给你讲清楚~~~首先我们先聊聊,什么是蜘蛛,那么这个事情需要追溯到很久之前了。当谷歌百度起来的时候,他们如何去抓取网页去展示呢?他们就利用爬虫,爬取每一个网页,我们来说一个简单的例子来证明这个事情 比如下面的样式 就是抓取了菩提网络博客的首页import requests # 修正:requests需调用具体方法(如get),并添加请求头模拟浏览器 url = 'https://www.1023.blog' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' } try: # 发送GET请求,设置超时时间(建议不超过10秒) response = requests.get(url, headers=headers, timeout=10) # 检查响应状态码(200表示成功) if response.status_code == 200: # 设置正确的响应编码(根据实际情况调整,此处假设为utf-8) response.encoding = 'utf-8' print(response.text) else: print(f"请求失败,状态码:{response.status_code}") except requests.exceptions.RequestException as e: print(f"请求异常:{e}") except Exception as e: print(f"其他错误:{e}")最后打印出来的就说html页面,那么搜索引擎接下来干的事情就是把问题提取出来 按照一定是索引存起页面来,当用户搜索关键词到时候进行匹配,如果存在的话,那么放出网页,展示给用户。当然这都是后话,如何去让搜索引擎展示的更多,涉及到另外一个技术SEO。接下来我们说的是那么蜘蛛对于网站看起来全部很好呀,但是其实你不知道的是,蜘蛛的威力要远远大于你想想的,当初博客园就是因为蜘蛛太多了!!!导致不得不屏蔽百度的蜘蛛,原文参考链接https://www.cnblogs.com/cmt/p/17833993.html那么AI和蜘蛛的关系也是很重要的,ai去查询信息总得去全网进行检索寻找,但是站长很难受,很简单,就是因为AI的任何无论API还是客户端,好点的给你展示一下你网站的链接,不好的话 根据不展示,直接那你数据就去训练模型了。也许你看到这篇文章的时候。我写的话已经提供AI去训练了,于是越来越多的网站选择要不去设置robots.txt(更加类似君子协定)要不干脆数据专门给蜘蛛留一块地方。